

域名启用DNSSEC可增加一层保护,减少域名受到DNS污染,首先将域名解析到cloudflare,之后点开DNS并找到启用DNSSEC如下图如果之前有操作过的,但是忘记保存记录可在数据记录中查看,如下图在namesilo后台找到自己的域名并点击想要启用DNSSEC的域名,如下图。接着点开Update如下图接着把cloudflare的数据记录中的数据输入下方选项,如下图上图的数据就是在下图这个地方获取的添加成功后会提示DS记录已成功添加如下图大概2分钟左右在cloudflare的后台也会看到有绿色的小钩钩说明DNSSEC已经成功启用。

优质段:116.179.32.*:新版百度蜘蛛,高权重段,一般抓取文章页。IP段位于山西阳泉联通。百度云计算阳泉中心位于世界最大中文搜索引擎百度公司创始人李彦宏的家乡山西省阳泉经济开发区东区。220.181.108.75:重点抓取更新文章的内页达到90%,8%抓取首页,2%其他。权重IP段,爬过的文章或首页基本24小时放出来。220.181.108.77:专用抓首页IP权重段,一般返回代码是30400代表未更新。220.181.108.80:专用抓取首页IP权重段,一般返回代码是30400代表未更新。220.181.108.82:抓取tag页面。220.181.108.83:专用抓取首页IP权重段,一般返回代码是30400代表未更新。220.181.108.86:专用抓取首页IP权重段,一般返回代码是30400代表未更新。220.181.108.89:专用抓取首页IP权重段,一般返回代码是30400代表未更新。220.181.108.91:属于综合的,主要抓取首页和内页或其他,属于权重IP段,爬过的文章或首页基本24小时放出来。220.181.108.92:同上98%抓取首页,可能还会抓取其他(不是指内页),属于权重IP段此段爬过的文章或首页基本24小时放出来。220.181.108.94:专用抓取首页IP权重段,一般返回代码是30400代表未更新。220.181.108.93:重点抓取内页,爬过的文章或首页基本24小时放出来。220.181.108.95:这个是百度抓取首页的专用IP,如是220.181.108段的话,基本来说你的网站会天天隔夜快照,绝对错不了的。220.181.108.97:专用抓取首页IP权重段,一般返回代码是30400代表未更新。220.181.108.115:重点抓取内页,爬过的文章或首页基本24小时放出来。220.181.108.119:专用抓取首页IP权重段,一般返回代码是30400代表未更新。220.181.108.156重点抓取内页,爬过的文章或首页基本24小时放出来。220.181.108.158:重点抓取内页,爬过的文章或首页基本24小时放出来。220.181.108.184:重点抓取内页,爬过的文章或首页基本24小时放出来。220.181.108.180:重点抓取内页,爬过的文章或首页基本24小时放出来。220.181.108.*:主要是抓取首页占80%,内页占30%,这此爬过的文章或首页,绝对24小时内放出来和隔夜快照的!一般成功抓取返回代码都是20000返回30400代表网站没更新,蜘蛛来过,如果是200064别担心这不是K站,可能是网站是动态的,所以返回就是这个代码。普通段:60.172.229.61:代表百度蜘蛛IP造访,准备抓取你东西,抓取网页的百度蜘蛛。61.129.45.72:代表百度蜘蛛IP造访,准备抓取你东西,抓取网页的百度蜘蛛。61.135.162.*:代表百度蜘蛛IP造访,准备抓取你东西,抓取网页的百度蜘蛛。61.135.168.*:抓取图片的百度蜘蛛。121.14.89.*:这个ip段作为度过新站考察期,很少。通常有它光顾的时候,网站基本上是没有排名的。123.15.**.**:百度图片爬虫。123.125.66.*:代表百度蜘蛛IP造访,准备抓取你东西,抓取网页的百度蜘蛛。123.125.71.*抓取内页收录的,权重较低,爬过此段的内页文章暂时被收录但不放出来,因不是原创或采集文章。124.166.232.*:可能为新版新站专属百度蜘蛛。125.90.88.*:广东茂名市电信也属于百度蜘蛛IP主要造成成分,是新上线站较多,还有使用过站长工具,或SEO综合检测造成的,没有多大用。159.226.50.*:百度蜘蛛。180.76.5.*:百度蜘蛛北京联通。180.76.5.87:百度蜘蛛北京电信。210.72.225.*:这个ip段不间断巡逻各站,就是路过一下。220.181.7.*:代表百度蜘蛛IP造访,准备抓取你东西,抓取网页的百度蜘蛛。垃圾段:百度自家61.135.186.*:百度联盟爬虫,百度统计。61.135.165.134:百度竞价蜘蛛北京联通。61.135.169.*:百度公司内部专用IP;111.206.198.*:百度渲染蜘蛛,专门抓取js、css和图片用的,百度站长工具落地着陆页检测IP。111.206.221.*:百度渲染蜘蛛,专门抓取js、css和图片用的,百度站长工具落地着陆页检测IP。117.34.74.66:百度竞价蜘蛛西安市电信。118.122.188.194:百度竞价蜘蛛。119.63.196.9:百度竞价蜘蛛。123.125.67.*:百度站长工具的IPsitemap。125.39.78.185:百度竞价蜘蛛天津联通。203.119.241.*:百度主动推送的IP。220.181.51.*:百度站长工具的IPsitemap。220.181.108.120:抓取/robots.txt。220.181.108.146:抓取/robots.txt。沙盒123.125.68.*:这个蜘蛛经常来,别的来的少,表示网站可能要进入沙盒了,或被者降权。180.76.15.*:降权蜘蛛,有这个ip说明网站不会在收录了,一直到这个ip段消失。220.181.68.*:每天这个IP段只增不减很有可能进沙盒或K站。
UserAgent就是我们在访问网站时自动发送本地的浏览器及系统信息,如果UserAgent是空的话,那就很有可能是垃圾评论发表器或者攻击器,如果你使用的是Nginx伺服器软体,我们只需要在「nginx.conf」文件中加入一段代码,即可封锁空UserAgent访问你的网站教学将下方代码通过任何方式添加到「nginx.conf」即可!:razz:提示:「nginx.conf」一般位于「/usr/local/nginx/conf/」资料夹内效果:加入本代码后,空UserAgent访问时,将会显示403错误!location/{if($http_user_agent~"^$"){return403;}}
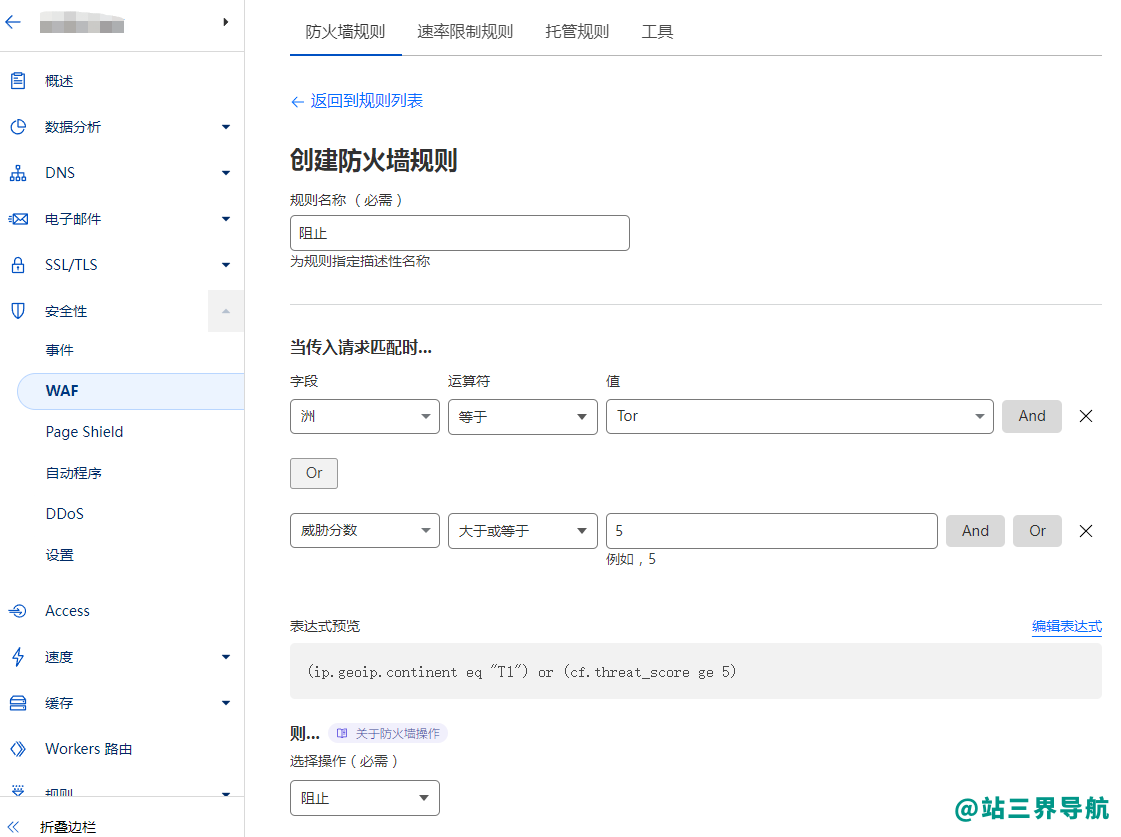
1.阻止规则Tor是洋葱路由,可以屏蔽。威胁分数大于等于5进行阻止。威胁分数正常访客不会触发。关于威胁分数:字段参考·Cloudflare规则集引擎文档2.验证规则第一段的意思是禁止HTTP1的版本因为正常访客访问都会是HTTP2,只有代理CC会是HTTP1,前提是你网站开启了https,不开启https这个规则不起作用。用户代理这个是防止一些奇奇怪怪的ua。威胁分数大于1的话自动弹出验证码,正常浏览器,干净的IP不会触发。最后一个是通过代理访问网站的。3.加一条蜘蛛规则,防止误伤

做过SEO或站长的都应该知道,网站要想做排名就必须使网站文章先收录,而网站内容收录由跟搜索引擎蜘蛛的来访抓取有很大的关系。搜索引擎蜘蛛,又被称为网页爬虫,网络机器人,在FOAF社区中间,也经常被称为网页追逐者,是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。另外它还有一些不常使用的名字,如:蚂蚁,自动索引,模拟程序或者蠕虫。那么,对于一个网站来说,是不是来网站爬行的搜索引擎蜘蛛越多越好呢?一、搜索引擎蜘蛛抓取网页的原理关于搜索引擎获得网页的工具,是一款爬行程序(俗称蜘蛛),蜘蛛程序每天都会爬行大量的网页,并将一些新的网页信息带到服务器以便进行网页索引的建立。搜索引擎蜘蛛抓取网页的原理可以说,互联网就是由一个个链接构成的,蜘蛛程序顺着这些链接爬行并发现网页信息,蜘蛛程序爬行每一个页面,当这个页面不再有新的链接信息的时候,它就返回,下次再到这个页面的时候,再去爬行(具体可查看马海祥博客的《搜索引擎工作的基础流程与原理》相关介绍)。当给它足够的时间,他就会找到互联网所有的网页信息(至少是被链接的),在爬行的时候,它还会不断的向服务器提供信息,所以我们在进行网站日志分析的时候,如果发现某一个网页被某个搜索引擎的蜘蛛程序程序爬行并成功抓取数据,那么,这个网页就很有可能被索引。所以,从SEO的角度来说,提高网页的索引数据(收录量)对于一个网站的搜索引擎优化(SEO)是非常有利的。当蜘蛛程序在爬行链接的过程中,它还会对爬行过的链接进行处理,因为链接需要载体(文字、图片或其他信息),发现链接载体并存储链接数据。所以这里我们要做的,就是努力增加蜘蛛爬行页面的频率(在以往的网站分析中经常提到),以保证我们网页在搜索引擎数据库中的索引是最新的。比如蜘蛛程序今天访问了网站的两个网页并成功抓取,隔了两个星期,它再来访问这两个页面的时候,这两个网页其中一个更新了,另一个确没有,那么,蜘蛛程序可能会在一个星期内再次回访更新过的那个网页,而在一个月后才去访问没有更新的那个网页,随着时间的推移,蜘蛛程序会更加频繁是爬行经常更新的网页,以达到更新服务器中的索引数据,向用户提供最新的网页信息。二、搜索引擎蜘蛛是不是越多越好?不论哪个搜索引擎的爬虫,来抓取你网站的页面的时候,肯定在消耗你的网站资源,例如网站的连接数、网络带宽资源(空间流量)、服务器的负载、甚至还有盗链等,那是不是所有的搜索引擎蜘蛛都是有用呢?另外,搜索引擎的爬虫来抓取你的页面数据后,它也不一定收用数据,只代表它“到此一游”留下痕迹而已,据马海祥了解有些搜索引擎只是过来找下它想要的资源,甚至还有很多是开发人员的蜘蛛测试。对于一个原创内容丰富,URL结构合理易于爬取的网站来说,简直就是各种爬虫的盘中大餐,很多网站的访问流量构成当中,爬虫带来的流量要远远超过真实用户访问流量,甚至爬虫流量要高出真实流量一个数量级。对于那些想提高网站有效利用率的网站,虽然设置了相当严格的反爬虫策略,但是网站处理的动态请求数量仍然是真实用户访问流量的2倍。可以肯定的说,当今互联网的网络流量有很大一部分的流量是爬虫带来的,因此反搜索引擎爬虫是一个值得SEO长期探索和解决的问题。所以,从SEO的角度来说,搜索引擎蜘蛛来网站访问并非越多越好,并且还要合理的屏蔽无效的搜索引擎蜘蛛的抓取。三、过多的搜索引擎爬虫对网站的影响既然对于网站来说,搜索引擎蜘蛛并非是越多越好,那么,这具体是因为什么原因导致的呢?1、浪费带宽资源如果你的网站带宽资源有限,而爬虫的量过多,导致正常用户访问缓慢,原本虚拟主机主机的连接数受限,带宽资源也是有限,这种情况搜索引擎爬虫受影响呈现更明显。2、过于频繁的抓取会导致服务器报错如果搜索引擎爬虫过于频繁,会抓取扫描很多无效页面,甚至抓页面抓到服务器报502、500、504等服务器内部错误了,蜘蛛爬虫还在不停使劲抓取。3、与网站主题不相关的搜索引擎爬虫消耗资源比如一淘网的抓取工具是一淘网蜘蛛(EtaoSpider),目前是被各大电子商务购物网站屏蔽的,拒绝一淘网抓取其商品信息及用户产生的点评内容。被禁止的原因首先应该是它们之间没有合作互利的关系,还有就是EtaoSpider爬虫是一个抓取最疯狂的蜘蛛,据马海祥对一些电商网站的测试发现:一淘网蜘蛛(EtaoSpider)的一天爬行量比“百度蜘蛛(Baiduspider)”“360蜘蛛(360Spider)”“SOSO蜘蛛(Sosospider)”等主流蜘蛛爬虫多几倍,并且是远远的多。重点是EtaoSpider被抓取只会消耗你的网站资源,它不会给你带来访问量,或者其它对你有利用的。4、无效的测试抓取一些搜索引擎开发程序员,它们写的爬虫程序在测试爬行。5、robots.txt文件也并非是万能肯定有很多人认为,在robots.txt设置屏蔽搜索引擎爬虫即可,或者允许某些特定的搜索引擎爬虫,能达到你预想效果。正规搜索引擎会遵守规则,不过不会及时生效,但是据我对马海祥博客的测试发现:实际上某些蜘蛛往往不是这样的,先扫描抓取你的页面,无视你的robots.txt,也可能它抓取后不一定留用,或者它只是统计信息,收集互联网行业趋势分析统计。6、不是搜索引擎蜘蛛,但具有蜘蛛的特性例如采集软件,采集程序,网络扫描e-mail地址的工具,各式各样的SEO分析统计工具,千奇百怪的网站漏洞扫描工具等等,这些抓取对网站没有任何好处!四、如何解决无效搜索引擎蜘蛛取的问题各种搜索引擎的蜘蛛爬虫会不断地访问抓取我们站点的内容,也会消耗站点的一定流量,有时候就需要屏蔽某些蜘蛛访问我们的站点。那么接下来,马海祥就根据自己的经验跟大家分享4种解决无效搜索引擎蜘蛛抓取的方法:1、只运行常用的搜索引擎蜘蛛抓取依据空间流量实际情况,就保留几个常用的,屏蔽掉其它蜘蛛以节省流量。2、通过服务器防火墙来屏蔽ip从服务器防火墙iptable直接屏蔽蜘蛛IP段、详细的IP,这是最直接、有效的屏蔽方法。3、WWW服务器层面做限制例如Nginx,Squid,Lighttpd,直接通过“http_user_agent”屏蔽搜索引擎爬虫。4、最后robots.txt文件做限制搜索引擎国际规则还是要遵循规则的。五、各大搜索引擎蜘蛛的名称抓取网站的搜索引擎蜘蛛是不是越多越好为了使大家找到适合自己网站的搜索引擎蜘蛛,马海祥也特意整理了一份最新的各大搜索引擎蜘蛛名称(大家要注意下写法的不同点,特别是大小写):1、百度蜘蛛:Baiduspider网上的资料百度蜘蛛名称有BaiduSpider、baiduspider等,那是旧黄历了。百度蜘蛛最新名称为Baiduspider,我通过对网站日志的检查还发现了Baiduspider-image这个百度旗下蜘蛛,是抓取图片的蜘蛛。常见百度旗下同类型蜘蛛还有下面这些:Baiduspider-mobile(抓取wap)、Baiduspider-image(抓取图片)、Baiduspider-video(抓取视频)、Baiduspider-news(抓取新闻)。2、谷歌蜘蛛:Googlebot这个争议较少,但也有说是GoogleBot的,谷歌蜘蛛最新名称为“compatible;Googlebot/2.1;”,不过,我还在马海祥博客的日志中发现了Googlebot-Mobile,看名字是抓取wap内容的。3、360蜘蛛:360Spider它是一个很“勤奋抓爬”的蜘蛛。4、SOSO蜘蛛:Sosospider5、雅虎蜘蛛:“Yahoo!SlurpChina”或者Yahoo!6、有道蜘蛛:YoudaoBot,YodaoBot7、搜狗蜘蛛:SogouNewsSpider

新手建站以后,对于蜘蛛引擎的关注必然不会少,因为大家建网站的目的就是做SEO关键词排名,最终以流量为导向,所以,希望蜘蛛更多的爬取自己网站!但是,很多人观看自己的网站日志文件的时候,会发现有部分蜘蛛引擎,会经常爬取自己的网站,比如说,YandexBot爬虫蜘蛛!这是俄罗斯的一家搜索引擎,我们一般把YandexBot爬虫蜘蛛叫做俄罗斯蜘蛛,如果你建设的是中文站,基本上这个蜘蛛是可以屏蔽的!有人会有疑问,建站之后,越多蜘蛛爬行,证明网站的价值越高,为什么要屏蔽这些蜘蛛呢?为什么要屏蔽YandexBot?因为我们的网站针对的是国内的搜索引擎,比如百度、搜狗、360这些,除非你做的是外贸网站,对于国外的蜘蛛引擎来说,有必要抓取!才不用屏蔽!当然,如果只是这些蜘蛛引擎对于我们网站的关键词和流量没有帮助的情况下,我们也可以不屏蔽,但是为什么我要强调必须屏蔽呢?因为,这些无用蜘蛛在爬行网站的时候,也是要浪费你的网站服务器资源的,占用你的CPU,大量蜘蛛爬行网站的情况下,对你的网站资源占用就会跟高,极容易造成网站的卡顿!甚至有一部分人也发现了,网站平时比较快,偶尔会慢几分钟,超级慢,服务器和域名解析之类都没有问题,慢几分钟之后,就会恢复原来的速度!这时候,极有可能是因为蜘蛛引擎在大量爬行你的网站造成的,所以,我们才会想办法屏蔽这些无用的蜘蛛!怎么屏蔽YandexBot蜘蛛?在你的网站的根目录中,找到robots.txt文件,顶部加入两行代码:User-agent:YandexBotDisallow:/这样,我们就可以把这个无用的俄罗斯蜘蛛YandexBot给屏蔽掉了,过几天之后,再检查网站日志,你就会发现,YandexBot不再到你的网站爬行了!
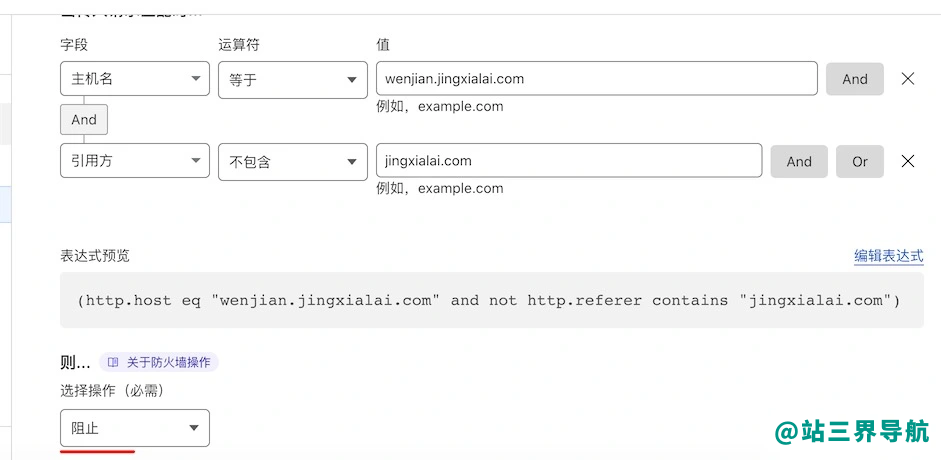
cloudflare默认有个Hotlink保护,但是这个只支持图像类的防盗链,不支持其他文件类型的。比如你有一个zip的文件,不希望其他网站调用,那么这个时候就需要用到CloudflareWAF的防火墙规则了。1、安全性-防火墙规则设置:一个阻止规则(http.hosteq"wenjian.zhansanjie.com"andnothttp.referercontains"zhansanjie.com")就是当主机名等于:wenjian.zhansanjie.com但是引用方不包含:zhansanjie.com的时候,就阻止访问。这个时候其他域名调用或者用浏览器直接访问这个文件,就会出现AccessdeniedErrorcode1020错误,就是拒绝访问。2、把ScrapeShield里面的Hotlink保护关掉。其他说明:这样设置只是防止其他网站调用你网站的文件,但是阻止不了用第三方客户端软件访问你网站文件地址。
CloudFlare最近上线了ArgoTieredCache缓存服务。关键还是免费的。真乃良心企业。今天pc6a学习分享小白就将来简单介绍下它。CloudFlareArgoTieredCache是什么官方介绍:ArgoTieredCacheArgo是一项服务,它在Cloudflare网络中使用经过优化的路由,更快、更可靠且更安全地为您的用户提供响应。TieredCaching是一种做法,在这种做法里,Cloudflare的全球数据中心网络分为上层和下层层次结构。为了控制源服务器与Cloudflare之间的带宽和连接数,仅上层会被允许从源服务器请求内容,然后负责将信息分发到下层。启用TieredCache后,Cloudflare将使用Argo性能和路由数据为源服务器动态查找单个最佳上层。这种做法通过限制可以向源服务器请求内容的数据中心的数量来提高带宽效率,可以减少源服务器负载,让网站的运营更具成本效益。小白讲解白话文:无ArgoTieredCache模式。用户请求CF后,由用户所在地节点(anycast访问节点)回源取内容。这过程种可能产生数据丢包等问题。且每个地方都需要回源取数据。美国用户、英国用户都访问一次。就要从美国/英国回源。有ArgoTieredCache模式。用户请求CF后,下层节点请求上层节点回源(上层节点在源站服务器附近)。上层与下层之间走CloudflareArgo优化线路。减少丢包。美国用户、英国用户都访问一次。只需回源一次,无需单独回源。节省服务器宽带和负载。注:ArgoTieredCache含故障转移功能,无需担心回源失败。目前小白的源站在香港。回源数据中心为香港HKG、故障转移节点为台湾TPE。优点都介绍完了。我们大概知道这个功能是啥玩意了吧。小白强烈建议开启它。ArgoTieredCache启用方法教程:CF面板–域名–缓存–TieredCache–选择即可。如下图:小白备注:虽然Argo服务是付费的。但是这个ArgoTieredCache是实打实免费的,可以放心大胆的开通。

最近听很多站长说,提交必应搜索,流量挺多的,然后我今天抽空去登录了必应站长后台。发现其实之前已经提交过了网站,就在前一年的事情了。说起登录的时候,我发现使用360极速浏览器,登录后,显示账户未授权,刚开始以为是被拉黑了。后面使用谷歌浏览器登录后,一切正常。第一时间把网站地图更新了,发现已经捉取失败,重新提交一下地图链接已经成功了。必应提交文章链接有三个途径:第一个主动提交文章url,第二个使用api提交,第三个提交网站地图链接。其实必应搜索流量还是有的,在后台可以精准看到某个关键词的展现数量和点击数。发现其实必应有收录自己的文章内页,但是没有收录了首页。先讲一下如何批量将全部文章链接提交一次到必应蜘蛛捉取。其实很简单,像我这样,在zblog应用中心,下载一款免费的网站地图插件,支持生成txt文件的。生成后打开,就可以了。注意:一次只能提交500个链接,所以如果自己的网站链接太多了,只能分批次去提交。提交后我发现陆续来蜘蛛捉取了。你想要必应收录你的网站,就不要屏蔽国外ip访问,我之前就是因为屏蔽了,所以导致现在很多链接已经失去了收录。目前来说使用cloudflare,防火墙规则里面可以设置不拦截搜索蜘蛛,自己设置了目前来说正常。而且最近cloudflare有一个新的功能名字叫:CrawlerHints。当使用Cloudflare的站点更改其内容时,爬虫提示会为搜索引擎和其他爬虫提供高质量的数据。这使得爬虫能够精确地进行爬取,避免浪费性爬取,并普遍减少源和其他互联网基础设施的资源消耗。爬虫提示如何工作?启用后,当我们认为您网站上的内容已更改并需要重新编制索引时,Cloudflare会将信号推送到运行大型抓取操作的网络(例如搜索引擎)。搜索引擎根据提供商的不同算法抓取您的网站。通常节奏,搜索引擎抓取您的网站是基于定期间隔或有关过去网站更新的数据,这些因素可能与现实世界的内容变化不一致。这种爬行方法不仅会损害客户页面排名,还会损害搜索引擎的运营成本和环境影响。CrawlerHints的目标是帮助搜索索引器在内容发生变化时做出更明智的决定,从而使互联网更环保、更节能。我是这样理解的:这个功能是不是有点类似于百度云加速里面的seo功能,能第一时间通知蜘蛛。毕竟你使用是它们的cdn,那边会储存到你的网站数据,调用时候很方便。然而cloudflare是国外的一个防护网站平台,会不会跟必应搜索有合作关系?不妨试一下。目前多提交一个搜索引擎多一份流量,做站长没必要“闭关锁国”。而且必应搜索也支持在国内直接访问,对于很多人,现在习惯性地使用必应来搜索问题。
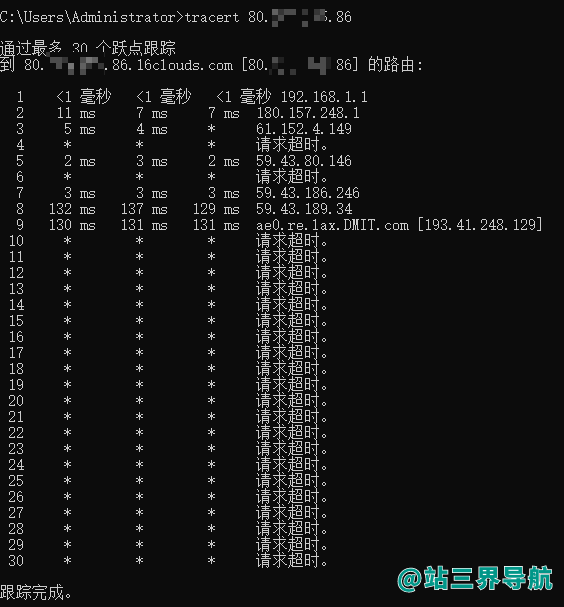
查看IP是否被墙,可以使用ping命令和tracert命令检测是否被墙。操作方法使用快捷键win+R打开运行窗口,输入cmd,点击确定按钮,启动了cmd命令窗口。输入ping*(*为你的ip),如果一直请求超时,说明IP被墙。或者输入输入命令tracert*(*为你的ip)。30跳之内,如果在12跳之后一直请求超时,说明IP被墙。(前面的还是国内路径,所以可以获取,12之后一般就是出国了,不能访问说明被拦截了)Tracert(跟踪路由)是路由跟踪实用程序,用于确定IP数据包访问目标所采取的路径。案例中是检测ip地址经过几个跃点。MacOS操作方法和win差不多,都是打开命令行,只是命令会稍微有点区别,ping命令都是一样的,tracert*在MacOS上为traceroute*。例如:











 中国互联网举报中心
中国互联网举报中心